 当前位置:
当前位置:在写爬虫前,我们要熟悉抓取的页面以及url结构规律,然后才能更有效率
例如北京到大同的航班查询url为
http://flight.qunar.com/schedule/fsearch_list.jsp?departure=北京&arrival=大同
那么我们就可以通过这个页面的城市来拼凑出所有的url地址
http://flight.qunar.com/schedule/alphlet_order.jsp
由于要使用多进程,我这里预先将查询到的所有有航班url写入到txt中,
python环境是python2版本,按照惯例导入需要使用的模块,
import requestsfrom bs4 import BeautifulSoupimport refrom multiprocessing import Poolimport sys
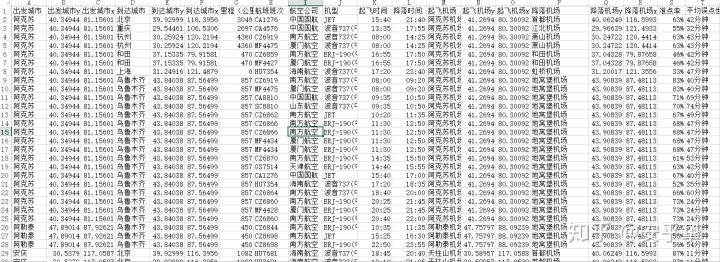
然后利用multiprocessing模块进行多进程分任务抓取页面信息,并使用美丽的鲜汤(BeautifulSoup)解析需要的内容存进txt中,信息如下
出发城市 出发城市y 出发城市x 到达城市 到达城市y 到达城市x 里程(公里) 航班班次 航空公司 机型 起飞时间 降落时间 起飞机场 起飞机场y 起飞机场x 降落机场 降落机场y 降落机场x 准点率 平均误点世间 周一班期 周二班期 周三班期 周四班期 周五班期 周六班期 周日班期 航班有效期开始 航班有效期结束
该过程我主要写了三个函数来实现业务逻辑:任务分配、包装请求和网页内容获取、页面有效信息提取。

然后基于百度的地理编码API获取出发城市、达到城市、出发机场、到达机场的经纬度坐标。
然后我就获得了全国15074条航班数据。
该过程所有代码附后,代码拙劣,见笑见笑。
通过分析获取的数据,我们看到:
目前全国有185个城市或地区有航班
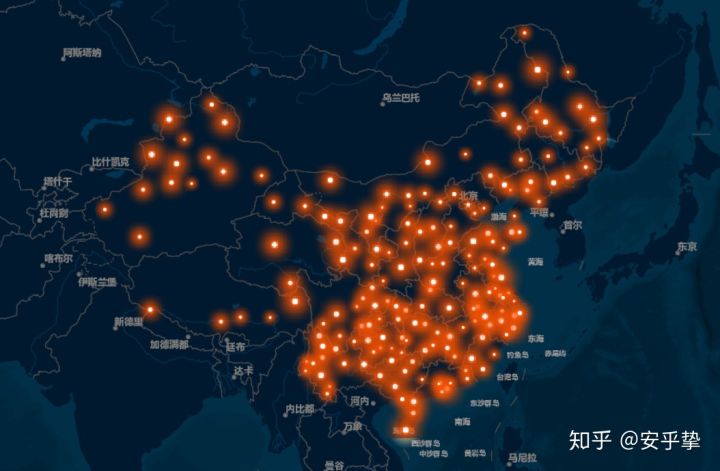
一共有214个机场用于民用航线的起降

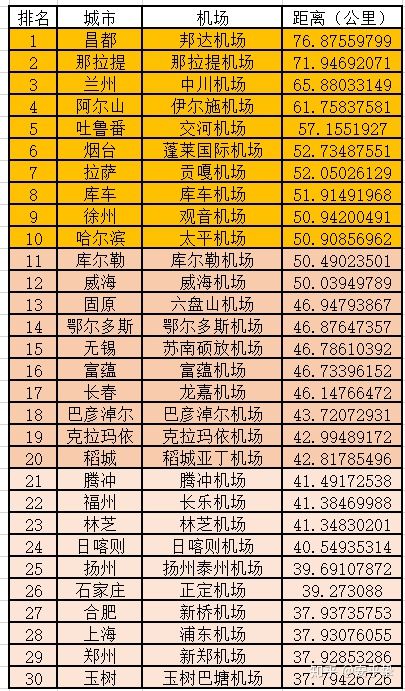
我们都知道,一般飞机场都建在城市郊区或者更远的地方,各城市与当地机场的距离最远的排名Top30如下,PS:生活在这些城市的小伙伴们有木有切身的体会呢?
另外,在一万五千次航班中,机型最多的是波音737(中),其次是空客A320(中),国产的新舟60(小)接近150架次
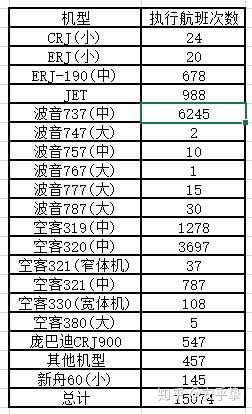
其他的信息,大家可以自行探索了,就不一一赘述了。
然后我们可以使用ArcMap中的xy to line工具生成全国的航班换线图
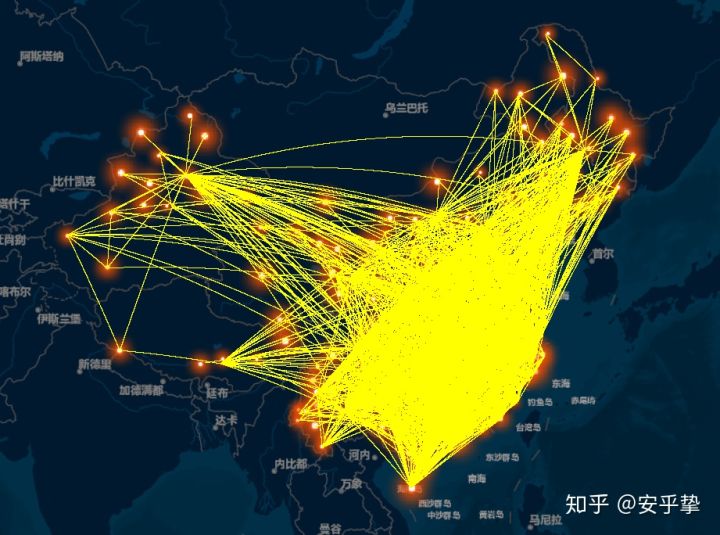
由于爬取的数据比较完整,完全可以动态展示。后期有时间会再写一篇教程。
最后附上源码和数据
PS:以上展示或者数据计算可能有误,欢迎指出并交流。
=======================
欢迎关注我的小小公众号! zyouzz
分享RS/GIS,无人机,物联网,大数据技术和资讯,萃取行业动向,为每天的进步助力!
=======================
excel数据(包含经纬度坐标)
链接:https://pan.baidu.com/s/149x089ZdxMQXZbymentYwQ 密码:p1rn
源码
import requestsfrom bs4 import BeautifulSoupimport refrom multiprocessing import Poolimport sysreload(sys)sys.setdefaultencoding('utf-8')def geturl(url):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
hbpage = requests.get(url, headers=headers).text
print hbpage
return hbpagedef flyin(city_citys,numm):
print '>>>>>进程%d开始>>>>>'%(numm+1)
# time.sleep(5)
pageinfo = []
for city_city in city_citys:
hbpage=geturl(city_city)
# print hbpage
bg=str(city_city.split('=')[-2]).replace('&arrival','')#始发
dg=city_city.split('=')[-1]#飞往
ft=(bg+dg)
print ft
if BeautifulSoup(hbpage, 'lxml').select('p[class="msg2"]'):
print '此线路无航班'
else:
hblc = BeautifulSoup(hbpage, 'lxml').select('em')[0].get_text()
print hblc
#航班班次 第一列
hbtitle=BeautifulSoup(hbpage,'lxml').select('span[class="title"]')
hbbc1=[]
hkgs1=[]
jixing1=[]
for ht in hbtitle:
hbbc=re.findall(r'\w.?\d*',ht.get_text())[0]#航班班次
hkgs=ht.get_text().split(hbbc)[0]#航空公司
jixing=ht.get_text().split(hbbc)[1]#机型
hbbc1.append(hbbc)
hkgs1.append(hkgs)
jixing1.append(jixing)
#起降时间 第二列
hbtime=BeautifulSoup(hbpage,'lxml').select('span[class="c2"]')[1:]
qfsj1=[]
jlsj1=[]
for qj in hbtime:
qfsj=qj.get_text()[:5]#起飞时间
jlsj=qj.get_text()[5:]#降落时间
qfsj1.append(qfsj)
jlsj1.append(jlsj)
#机场 第三列
hbjc=BeautifulSoup(hbpage,'lxml').select('span[class="c3"]')[1:]
qfjc1=[]
jljc1=[]
for jc in hbjc:
qfjc=jc.get_text().split('机场'.decode('utf-8'))[0]+'机场'.decode('utf-8')#起飞机场
jljc=jc.get_text().split('机场'.decode('utf-8'))[1]+'机场'.decode('utf-8')#降落机场
qfjc1.append(qfjc)
jljc1.append(jljc)
#准点率 第四列
zdl=BeautifulSoup(hbpage,'lxml').select('span[class="c4"]')[1:]
zdl1=[]
wdsj1=[]
for zd in zdl:
zdlv=zd.get_text().split('%')[0]+'%'
wdsj=zd.get_text().split('%')[1]
zdl1.append(zdlv)
wdsj1.append(wdsj)
#班期 第五列
bq=BeautifulSoup(hbpage,'lxml').select('span[class="c5"]')[1:]
# xx=[]
duty1 = []
for xq in bq:
week=re.split('\">\d',str(xq))[:-1]
week1=[]
ii=1
for day in week:
if ii==1:
dd='周一'
elif ii==2:
dd = '周二'
elif ii==3:
dd = '周三'
elif ii==4:
dd = '周四'
elif ii==5:
dd = '周五'
elif ii==6:
dd = '周六'
elif ii==7:
dd = '周日'
if day[-4:]=='blue':
duty='%s有班期'%dd
else:
duty='%s没有班期'%dd
ii+=1
week1.append(duty)
duty1.append(week1)
#班期有效期 第七列
bqyxq = BeautifulSoup(hbpage, 'lxml').select('span[class="c7"]')[1:]
qs1=[]
js1=[]
for yxq in bqyxq:
yxs=yxq.get_text()[:10]#起始
yxe=yxq.get_text()[:10]#结束
qs1.append(yxs)
js1.append(yxe)
print hbbc1
for li in range(len(hbbc1)):
print '标记'
pageinfo.append(bg + ',' + dg + ',' + hblc + ',' + hbbc1[li] + ',' + hkgs1[li] + ',' + jixing1[li] + ',' + qfsj1[li] + ',' + jlsj1[li] + ',' + qfjc1[li] + ',' + jljc1[li] + ',' + zdl1[li] + ',' + wdsj1[li] + ',' + duty1[li][0] + ',' + duty1[li][1] + ',' + duty1[li][2] + ',' +duty1[li][3] + ',' + duty1[li][4] + ',' + duty1[li][5] + ',' + duty1[li][6] + ',' + qs1[li] + ',' + js1[li] + '\n')
print bg + ',' + dg + ',' + hblc + ',' + hbbc1[li] + ',' + hkgs1[li] + ',' + jixing1[li] + ',' + qfsj1[li] + ',' + jlsj1[li] + ',' + qfjc1[li] + ',' + jljc1[li] + ',' + zdl1[li] + ',' + wdsj1[li] + ',' + duty1[li][0] + ',' + duty1[li][1] + ',' + duty1[li][2] + ',' +duty1[li][3] + ',' + duty1[li][4] + ',' + duty1[li][5] + ',' + duty1[li][6] + ',' + qs1[li] + ',' + js1[li] + '\n'
print pageinfo
return pageinfodef urlsplit(urls,jiange):
urli=[]
for newj in range(0,len(urls),jiange):
urli.append(urls[newj:newj+jiange])
return urliif __name__=='__main__':
finalre=[]
files = open(r'C:\Users\username\Desktop\url.txt', 'r')
urls=[]
for url in files.read().split():
urls.append(url)
urlss=urls[:6]
urlll=urlsplit(urlss,2)
p = Pool(2)
result=[]
for i in range(len(urlll)):
result.append(p.apply_async(flyin,args=(urlll[i],i)))
p.close()
p.join()
print result
for result_i in range(len(result)):
print result[result_i]
fin_info_result_list = result[result_i].get().decode('utf-8')
finalre.extend(fin_info_result_list)
filers=open(r'C:\Users\username\Desktop\url55.txt','a+')
for fll in finalre:
filers.write(str(fll).encode('utf-8'))






